
Situation:
Businesses on Yelp struggle to extract actionable insights from millions of customer reviews. City planners and users also lack clear ways to identify hotspots, trends, and satisfaction patterns from large-scale Yelp data. Our team was tasked with making sense of 9GB of raw Yelp datasets (7M+ reviews).
Task:
Develop an analytics pipeline that could clean, process, and analyze Yelp reviews at scale. The project aimed to cluster businesses, classify user behavior, perform topic modeling, and run sentiment analysis to uncover actionable insights for both customers and business owners.
Action:
- Preprocessed and cleaned data (handled missing values, tokenization, lemmatization, stopword removal).
- Applied K-means clustering to identify 3 main business types: Premium Amenities, Selective Convenience, and Tech-Friendly Services.
- Clustered users based on engagement (“cool” vs. low-engagement users).
- Implemented LDA topic modeling to identify frequent discussion themes in reviews (e.g., service speed, food quality).
- Used Spark NLP with a pre-trained IMDB sentiment model to classify reviews into positive, neutral, and negative.
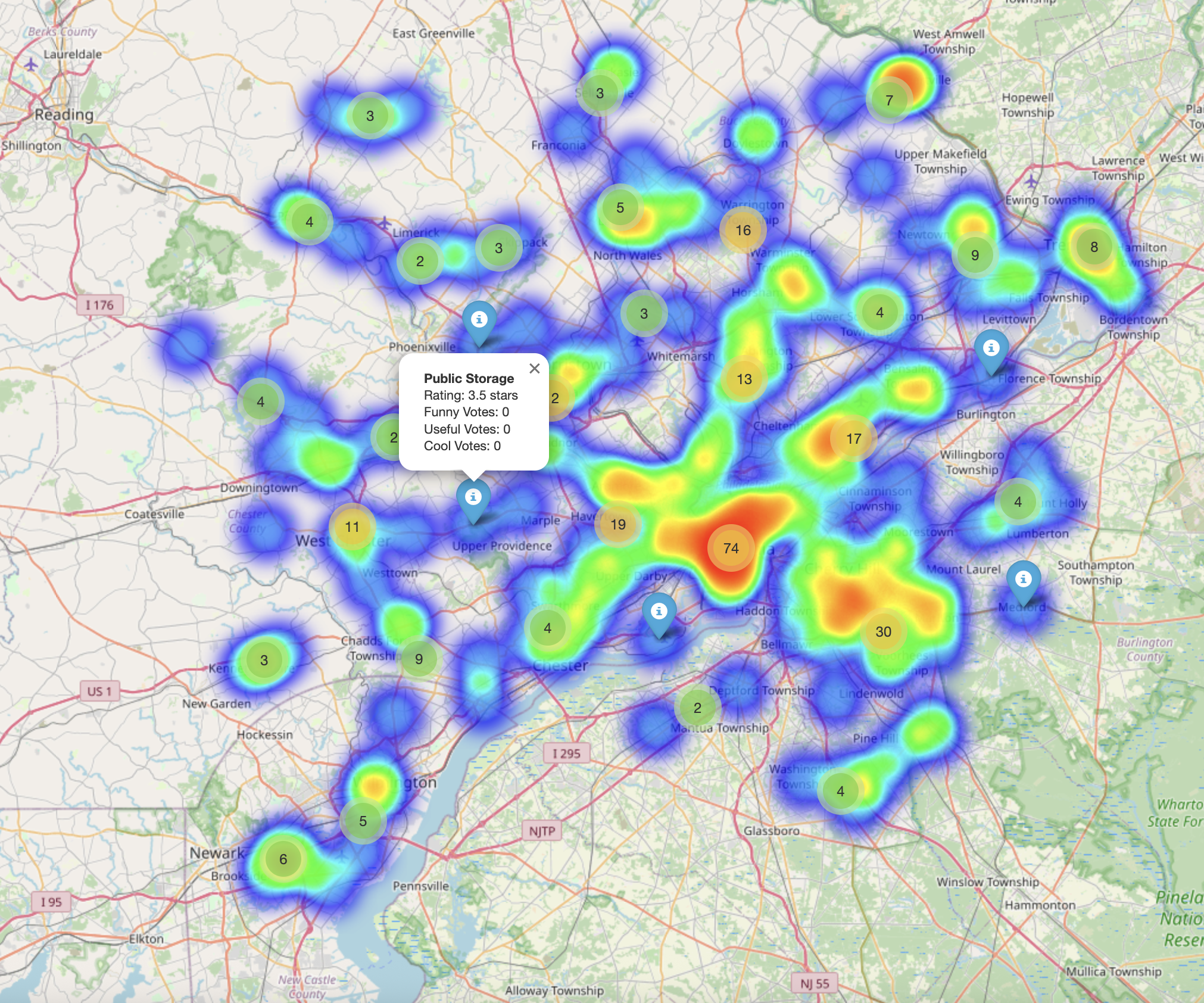
- Deployed interactive visual dashboards on Netlify for easy exploration.
Result:
- Reduced raw, unstructured text into clear, actionable insights for businesses and customers.
- Showed that positive reviews dominate, but negative reviews make up ~1/3, highlighting improvement areas.
- Business clustering revealed service-oriented patterns, guiding owners on where to position themselves.
- Delivered an interactive web app for stakeholders to explore results.
Technical Details
- Data Size: 9GB of Yelp datasets, 7M+ reviews processed.
- Tools & Stack:
- Big Data: Apache Spark (MLlib), Dataproc (Google Cloud)
- NLP: Spark NLP (
sentimentdl_use_imdbpre-trained model), tokenization, lemmatization, stopword removal, TF-IDF, and LDA topic modeling. - Clustering: K-means for business attributes and user “coolness” clustering.
- Visualization: Interactive dashboards built with Python & hosted via Netlify.
- Steps & Methods:
- Data Cleaning & Preprocessing → handled missing values, standardized attributes, tokenized & normalized text.
- Business Clustering → identified three distinct service-oriented groups.
- User Clustering → grouped reviewers into “trendy/cool” vs. low-engagement segments.
- Topic Modeling (LDA) → surfaced common discussion themes across millions of reviews (e.g., service speed, food quality, ambiance).
- Sentiment Analysis → applied Spark NLP model pre-trained on IMDB reviews to classify Yelp reviews into positive, neutral, or negative.
- Challenges & Solutions:
- Challenge: Long runtimes due to massive dataset + Spark MLlib’s limited NLP features.
- Solution: Leveraged Spark NLP pipelines + Google Dataproc cluster for distributed processing, integrating seamlessly with Spark MLlib.
